深入JVM(一)类加载过程和内存分配
本篇需要完成的内容是完成对对象从加载到创建过程的分析,与过程中的内存分配的方式等进行总结
内存区域
在分析对象创建过程前,需要先了解Java虚拟机中对内存区域的划分与管理。
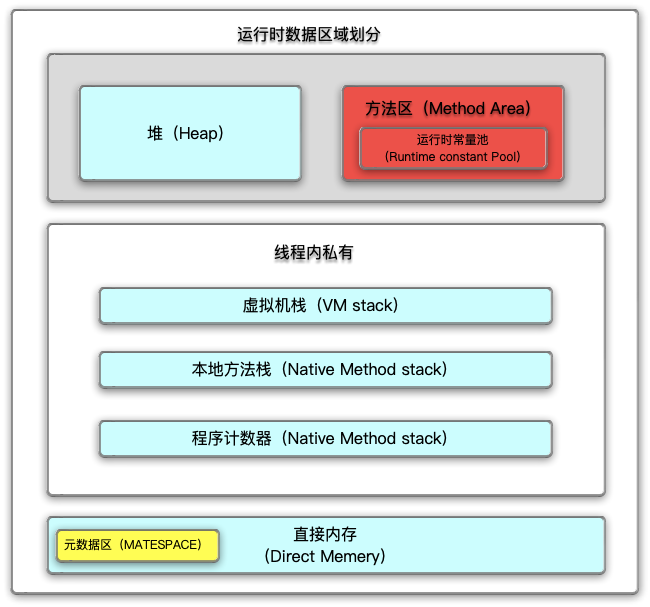
红色部分的方法区在1.8之后已经被移除,变为元数据区,红色内的运行时常量池已经成为堆中的一部分使用!!
上图中展示了Java虚拟机在运行时对管理的内存区域的划分。其中,分为线程私有的程序计数器、本地方法栈、虚拟机栈和线程共享的堆与方法区和直接内存。
1. 程序计数器
程序计数器是线程私有的、当前线程所执行的字节码的行号指示器,就像名字一样,它是可以看做计数的,每一条指令执行完后,会挪动程序计数器的指针,并指向下一条指令。(就像在平时debug一样)。
- 占用大小:程序计数器占用非常小的部分
- 生命周期:跟随线程的创建而创建,销毁而销毁
- 作用:简单来说可以执行该线程执行字节码的位置。在多线程切换的情况下也能够知道当前线程执行的位置。
2. Java虚拟机栈
虚拟机栈有一个一个的栈针组成,而每一个栈针内由局部变量表、操作数栈、动态链接、方法出口信息组成。线程的方法调用过程(方法调用链)会将其中的每一个方法依次压入栈中,最后在调用过后,依次出栈,也就是说,方法执行的过程也就是栈针压栈到弹出的过程。
一个线程中方法的调用链可能会很长,很多方法都同时处于执行状态。对于JVM说,在活动线程中,只有位于JVM虚拟机栈栈顶的元素才是有效的,即称为当前栈帧,也就是当前执行的方法。
局部变量表
局部变量表是我们在使用和了解Java虚拟机栈的主要部分,是变量值的存储空间,主要存放了编译时可知的基本数据类型(boolean、byte、char、short、int、float、long、double)和方法引用(reference)。在编译时,局部变量表的空间就确定下来。
操作数栈
操作数栈在方法执行的过程中,起到了对常量或者变量暂存和计算的作用,当方法开始时,操作数栈时空的,随着方法的进行,会将局部变量表中或者实例对象中,复制常量变量到操作数栈,再随着方法的执行,进行数据的运算。最后出栈返回给方法调用者。
和局部变量表相同的是,操作数栈的栈的深度在编译时就已经确认下来。
动态链接
一个方法调用另一个方法时,会通过寻找符号引用的方式查找到直接内存地址。而方法的符号引用存在于运行时常量池中。
在每一个栈针中,会通过栈针中的动态链接,来持有方法的符号引用。能够动态的寻找到方法对应的内存地址完成调用。
方法出口信息
方法返回时可能需要在栈帧中保存一些信息,用来于恢复调用者(调用当前方法的方法)的执行状态。
如果正常返回,会在调用者的栈针中保存调用方法的返回值,而被调用者的栈针可能会保存调用者当前程序计数器的值。
如果异常退出,也就是在调用过程中发现异常,调用者的返回值将由异常处理器返回,而被调用者中就不可能存在调用者的计数器值。
实例
通过下面的代码,来看虚拟机栈的调用返回过程和操作数栈的入栈出栈过程。
源程序:
1 | public class NewObject { |
反编译后的程序:
1 | public static void main(java.lang.String[]); |
调用过程是:先通过在main方法里面创建一个newObject对象,再调用其中的add方法。其中newObject的过程先略过,后面讲,先看add方法执行的过程。
在add方法内,每次会将int类型的值先推到栈顶,然后执行赋值操作,将赋值的变量保存到局部变量表中,最后计算后将结果return。
3. 本地方法栈
虚拟机栈为虚拟机执行 Java 方法 (也就是字节码)服务,而本地方法栈则为虚拟机使用到的 Native 方法服务。
和虚拟机栈相同,每次方法执行时,都会创建一个栈针,存放本地方法的局部变量表、操作数栈、动态链接、方法出口信息。
4. 堆
堆是Java虚拟机管理内存中的最大的部分,也是进行GC主要部分。几乎所有的实例变量在堆中分配内存,少数小的对象可能在栈上分配。
在栈上分配的好处,首先快,其次不需要额外的垃圾回收的介入即可完成内存的释放。
在1.7之后,字符串常量池从方法区中挪到了堆中
5. 方法区
方法区和堆一样是线程共享的内容,它用于存储已被虚拟机加载的类信息、常量、静态变量、即时编译器编译后的代码等数据。
方法区是Java虚拟机定义的规范,在1.7之前,Hotspot虚拟机使用永久代实现方法区。在1.7后,使用了元空间区实现方法区。两者的差异在于元空间使用的是直接内存,整个永久代有一个 JVM 本身设置固定大小上限,无法进行调整,而元空间使用的是直接内存,受本机可用内存的限制,虽然元空间仍旧可能溢出,但是比原来出现的几率会更小。
运行时常量池
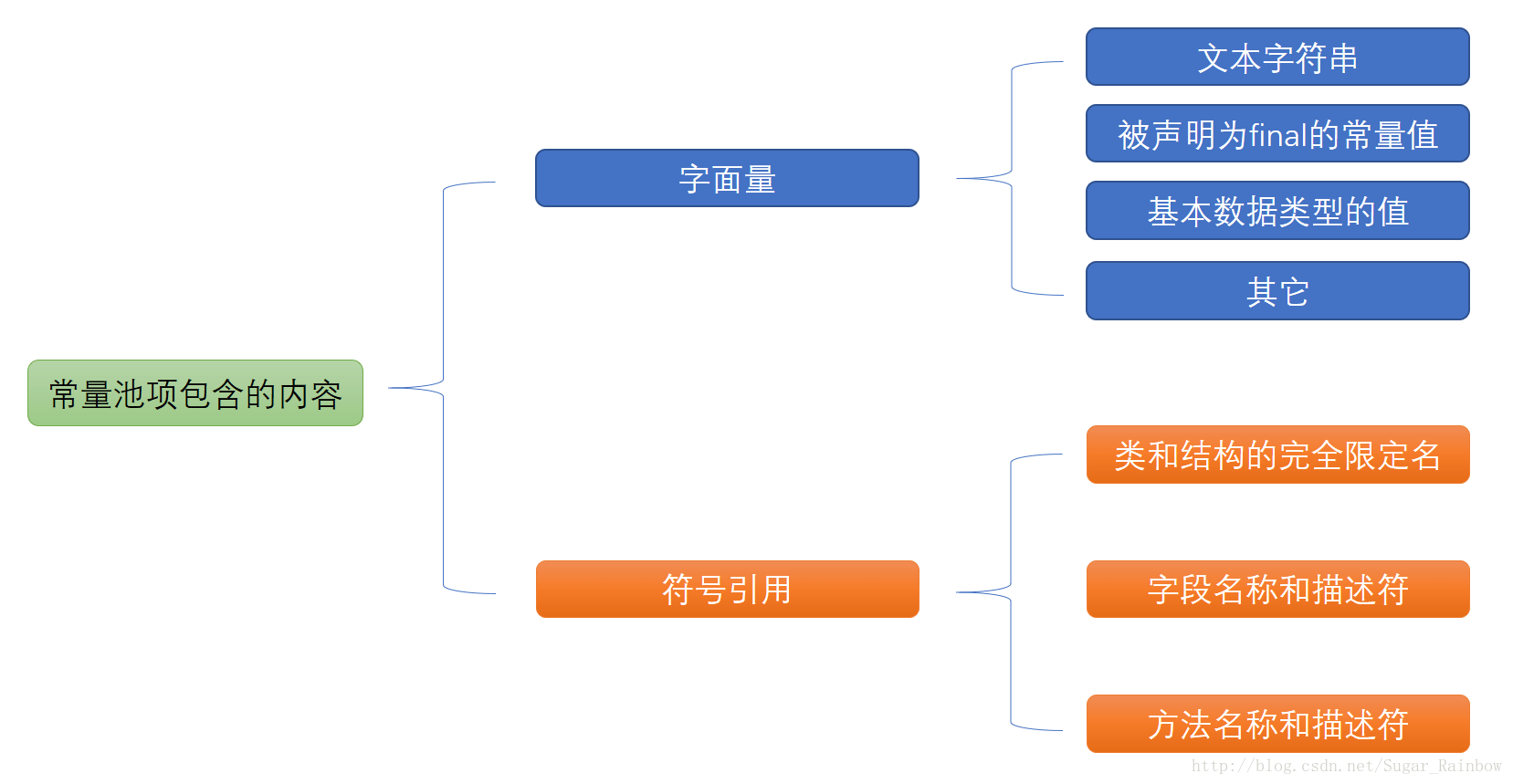
有三个比较容易混淆的概念,什么是类常量池,什么是运行时常量池,什么是字符串常量池,三者的区别是什么。
- 类常量池存在于字节码文件中,在字节码文件中存在类的常量池,其中存放两个类常量:字面量和符号引用,其中字面量的含义就是文本字符串和final修饰的常量值等。符号引用包含import的包、类和接口的全限定名、字段名称和描述符、方法类型和引用等等。
- 运行时常量池存在于内存中,在类加载的过程时,会将存在于字节码中的类常量池中的内容加载到运行时常量池中。相较于类常量池,运行时常量池具有动态性,不一定是在编译时期就确定的放入的。
- 字符串常量池,也叫做StringTable,在java7之后被放到了堆内,存放了字符串常量和字符串对象的引用。在class中的内容加载到运行时常量池后,在解析阶段,会把符号引用替换为直接引用,解析的过程会去查询字符串常量池,以保证运行时常量池所引用的字符串与字符串常量池中是一致的。
下图表示运行时常量池中的内容:
方法区和常量池_Java_屌丝程序员的奋斗之路-CSDN博客
6. 直接内存
直接内存并不是虚拟机运行时数据区的一部分,也不是虚拟机规范中定义的内存区域,但是这部分内存也被频繁地使用。
对象创建过程和对象布局
对象的创建过程
使用new关键字创建对象的过程分为5步,类加载检查、内存分配、初始化零值、设置对象头、执行init方法。参考下图:

1. 类加载检查
虚拟机遇到new指令时,会先进行类加载检查,如果再运行时常量池中未发现类的符号引用,则先去加载、解析、初始化类这一些列类加载到内存中的过程。
2. 分配内存
在类加载到内存后,对象在堆中分配的大小已经确定,利用指针碰撞或者空闲列表的方式将堆中指定大小的空间分配给新创建的类对象。
3. 初始化零值
在为对象分配完内存后,首先需要对对象的初始化零值,来保证对象不手动赋值也能够正常被访问。此时的对象处于半初始化状态。
4. 设置对象头
在初始化零值后,还需要为对象设置头部信息,包括Mark Word、Kclass Word、数组长度(如果是数组的话),具体会在后面提到。
5. 执行init方法
通过init方法,为对象真正的赋值,当执行init方法后,一个需要的对象才产生出来。
下面通过反编译的代码来看创建一个Object对象的过程:
1 | public static void main(java.lang.String[]); |
通过javap反编译可以看出一个对象,通过使用new命令后在堆中申请一块内存空间后,将o推到栈顶,使用invokespecial命令进行初始化,最后使用astore命令将对象o和创建的对象关联到一起。
对象布局
一个对象包含三个部分,分别为对象头、实例数据(对象体)、Padding对其字节。
对象头(Header)
在对象头中包含了三个部分:Mark Word、Class Pointer、数组长度(如果是数组)
- Mark Word:MarkWord中包含了自身的hashcode,gc的分代信息和锁标志位等,其中当上锁、上不同的锁的时候,头部信息都会出现不同的变化,具体占用长度和信息可以参考下图:
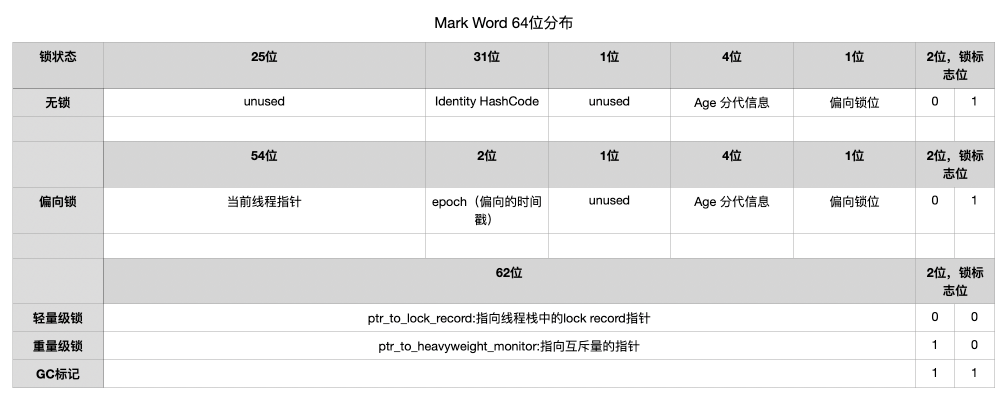
- Class Pointer: 在Class Pointer中包含了对方法区中的类元数据的引用,在64位系统下,如果不开启指针压缩时,会比32位多占二分之一的空间,所以在1.6之后,通过使用JVM的参数
-XX:+UseCompressedOops可以开启指针压缩将原来的8字节压缩为现在的4字节。 - 数组长度:如果当前对象时数组时,会额外产生一部分空间存储数组的长度
实例数据(Instance Data)
对象中主要的内容,存放实例数据,包括了对象的所有成员变量,其大小由各个成员变量的大小决定。
对其字节(Padding)
Java对象占用空间是8字节对齐的,即所有Java对象占用bytes数必须是8的倍数。
观察对象空间实例
1 | public static void main(String[] args) { |
当使用上面的方式创建一个对象o和一个数组对象arr时,利用openjdk的jol(Java Object Layout)工具进行内存的分析,产生如下的分析结果:
1 | java.lang.Object object internals: |
因为当前环境为64位,所以生成对象的大小应为8的倍数。可以看到对象o的layout中,前8个字节表示64位的MarkWord,之后4个字节表示KlassWord,最后四个字节并没有内容,是loss掉的,用于补齐字节用的,保证能够被8整除。
而在下面的数组对象arr中,可以看到最后的四个字节并不是对其,而是存储量数组的长度,而最后的字节表示了对象体,也就是初始化的数组内容。
在使用 -XX:-UseCompressedOops 关闭指针压缩时,观察对象o所占大小,发现大小未发生变化,然而原来的padding字节不见了,class pointer 变为了8个字节,一共16个字节,所以不需要padding来对其空间。
1 | java.lang.Object object internals: |
补充:javap和jol工具
- 使用JDK中自带的javap对class文件进行反编译,能够获得反编译到的执行过程。
- 使用IDEA中的插件:Jclasslib可以更具体的看反编译的代码和常量池中的内容
- 使用jol可以查看对象布局,使用方法,将OpenJDK中的jol的jar包加入到项目中,在main方法中使用ClassLayout静态方法解析对象后输出:
1 | <dependency> |