线上内存溢出分析
系统变慢,打开页面变卡,使用top命令查看cpu和内存情况后,发现在使用系统时,CPU 飙高。
针对此问题,展开排查。
排查产生原因
首先,使用 arthas 工具或者使用 jstack 查看 java 运行中的线程状态,查看哪些线程占用cpu过高,在使用时,发现为gc线程。
然后,使用 jstat 或者 arthas 中的 dashboard 命令 进行确认,发现堆中新生代老年代空间已满,每过十几秒就在进行一次full gc。所以,可以分析出CPU飙高的原因为内存溢出。
内存溢出原因分析
因为要进行内存溢出情况,需要拿出堆转储信息,所以,在无人使用系统时,使用 jmap 命令获取堆转储信息:
1 | jmap -dump:format=b,file=heapdump.hprof pid |
需要注意的是,使用 jmap 时,会使 JVM 处于 STW(stop the world) 状态,所以尽量不要在生产上有人使用时使用该命令,否则会导致非常长的时间停顿。
在拿到堆转储信息后,使用MAT(Memory Analyzer Tool)工具进行分析,装载文件后,得到如下图中的内容:
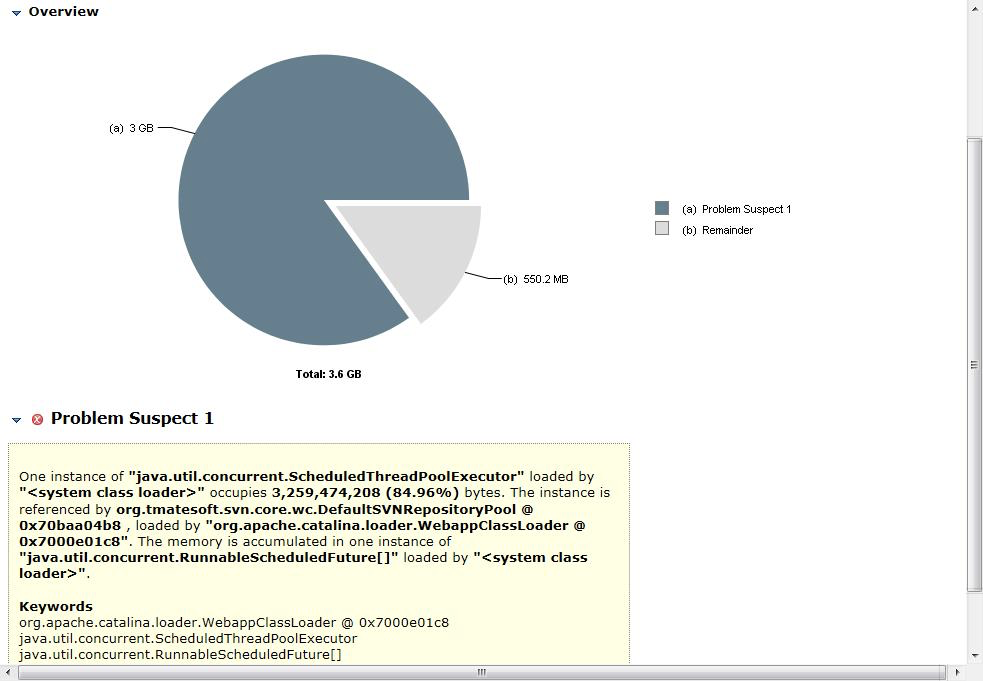
发现DefaultSVNRepositoryPoll引出的对象占用了3.6个G的空间(整个JVM分配空间为4个G),所以可以确定,是这个类生产 RunnableSecheduleFuture 对象的问题。
对 DefaultSVNRepositoryPool 进行分析,找问题
在前面已经分析出是DefaultSVNRepositoryPool引出的内存溢出,所以直接在IDEA中搜索到这个类,进入到该类,查看是否有相关 RunnableSecheduleFuture 方法。
- 首先确认哪里引用到了该类
一切还要从SVN上传文件说起,SVN上传文件有几个步骤:
1 | //1. 判断路径是否存在; |
其中对获取SVNClientManipulator时,其实是获取一个client客户端,整个过程可以用一个简单的sequence图来说明:

- 然后对DefaultSVNRepositoryPool内部排查
在引用到的 DefaultSVNRepositoryPool 的构造方法内,可以看到
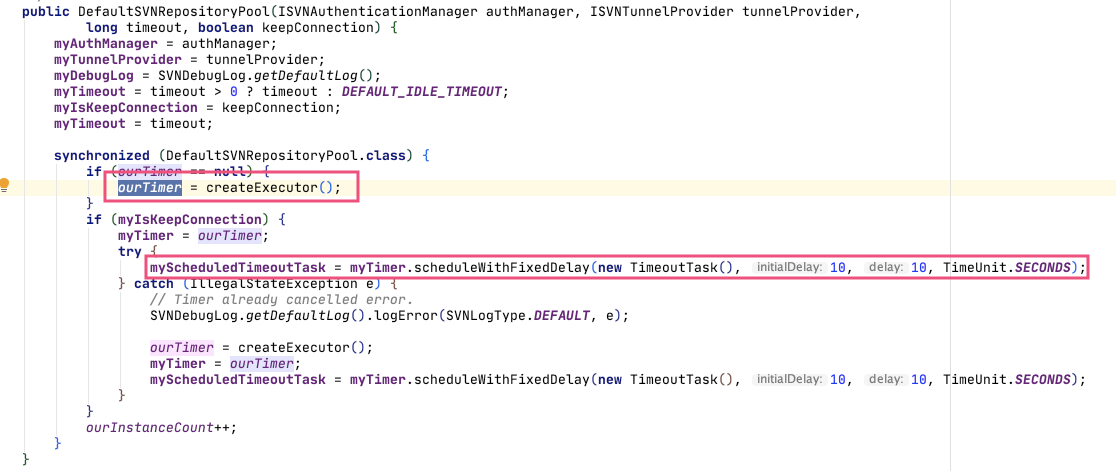
这里有两个Timer,作为全局的变量,可以看到作用是从10秒开始,没10秒执行一次 TimeOutTask() 方法。而这里的 myScheduledTimeoutTask 正是 ScheduledFuture 类型的。
如果不确认该类是否为溢出的对象,可以再进入到scheduleWithFixedDelay中。可以看到返回的正是RunnableScheduledFuture 对象。
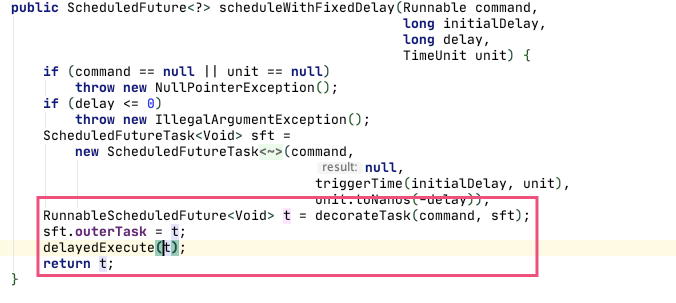
此时就可以由刚才的seq图往回推
最终问题有可能出现在在 svnCommonService 中创建了过多的 SVNClientManipulator 。
SVN上传代码排查
是否为上述分析的原因,需要在svnCommonService代码中确认。
- 对现有的SVN上传代码过程分析
svnFileJsonArray 将json解析为array,循环每个数组中的内容,进行文件上传。
首先SVNClientManipulator的创建发生在循环内,也就是说一次请求上传多个文件,则会创建多个客户端。此处为导致问题的主要原因。
其次,在代码内没有发现同步区域,而且大部分内容是需要查询表、插入表,在高并发的情况下可能会出现 mysql 的 lock wait 异常,最终导致文件无法上传的错误。
最后,现有因为代码是一个请求创建一个线程,n次请求就产生n个线程,这在高请求量的情况下出现问题的概率非常大。
基于以上三点进行代码上的修改
问题代码修改
- 针对SVNClientManipulator的创建发生在循环内
将json中取出一人或者直接传进一个处理人,创建client,减少client的创建次数
- 针对一次请求创建一个线程,修改为使用线程池,默认线程池的coreSize为8,核心数*2
- 针对同步代码块,使用sycronized进行同步代码块。
进阶修改:
上述修改后,可以满足过程,但是实际上大部分代码会使用sycronized进行包裹,同时进行的线程只有一个,所以提前创建多线程是占用内存的时间的。
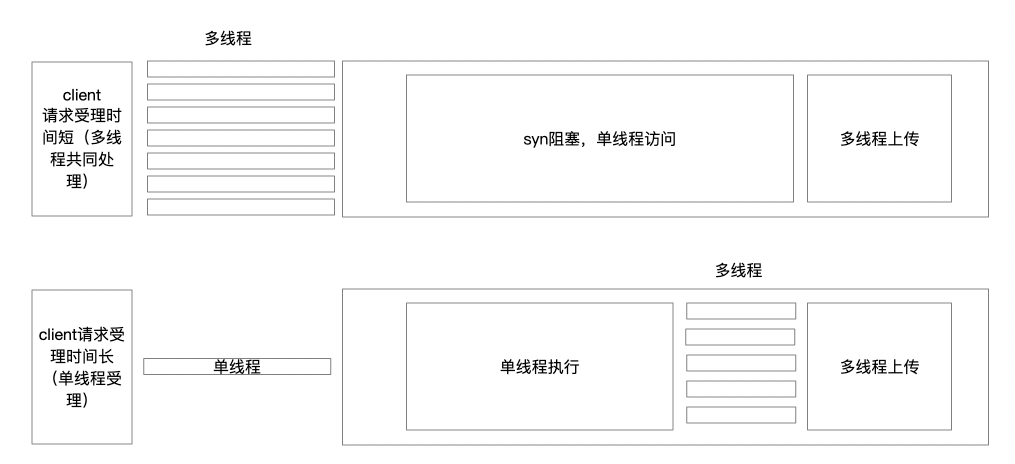
最终修改为:
- 使用单线程处理请求,单线程处理业务代码,避免了加锁解锁的消耗
- 仅仅在上传文件时,使用线程池进行文件上传
插曲:为什么DefaultSVNRepositoryPool没有回收掉
这里涉及到客户端连接SVN的状态,默认连接状态时 keepAlive 的,但是不需要手动进行连接的关闭。
一个客户端启动一个全局的Timer,这个Timer没10秒检测一下是否可以关闭连接,可以关闭连接的条件是 这个连接在 60 秒内没有再次访问过SVN。
但是,因为task是需要线程进行执行的,当创建非常多的pool时,timer可能取不到CPU时间片来执行task,所以就在一直等待,导致链上的所有对象,虚拟机都无法进行回收,最终导致内存溢出。
其他
一、JVM调优参数
线上分为三台机器,而应用占其中一台,总内存为16g,针对此环境修改JAVA_OPTS
1 | JAVA_OPTS="-server -Xms8192m -Xmx8192m |
针对其中参数含义解释:
- -XX:+UseGCLogFileRotation GCLog文件输出
- -XX:NumberOfGCLogFiles=5 GCLog文件数量
- -XX:GCLogFileSize=20M GCLog文件大小
- -XX:+PrintGCTimeStamps 打印GC耗时
- -XX:+PrintGCDetails 打印GC回收的细节
- -XX:HeapDumpPath=./java_pid
.hprof :堆内存快照的存储文件路径。文件名一般为java_ _ _ - -XX:+HeapDumpOnOutOfMemoryError 在OOM时,自动输出一个dump文件
二、JDK自带工具使用
- jps
JPS(Java Virtual Machine Process Status Tool),可以显示进行中的Java线程。
使用方式:jps [options] [hostid]
- jstat -gc
jstat(Java Virtual Machine statistics monitoring tool),能够查看JVM的使用情况
使用方式:jstat [ generalOption | outputOptions vmid [ interval [ s|ms ] [ count ] ] ]
如: jstat -gc -h3 31736 1000 10
- jstack
jstack(Java stack trace)是Java的堆栈分析工具。
两个功能:
- 针对活着的进程做本地的或远程的线程dump;
- 针对core文件做线程dump。
使用方式:jstack [ option ] pid
可将堆栈输出到指定文件中:jstack -l PID >> jstack.out
- jmap
jmap(Java memory map),它可以生成 java 程序的 dump 文件, 也可以查看堆内对象示例的统计信息、查看 ClassLoader 的信息以及 finalizer 队列。
jmap -dump:format=b,file=heapdump.hprof pid
- JVisualVM
用来监测JVM内存和线程使用情况,可以远程连接
三、其他分析工具
- MAT
用来分析堆转储信息,能够分析内存溢出问题
- Arthas
可以实现JDK中工具所有功能,更直观。还能够线上热部署。