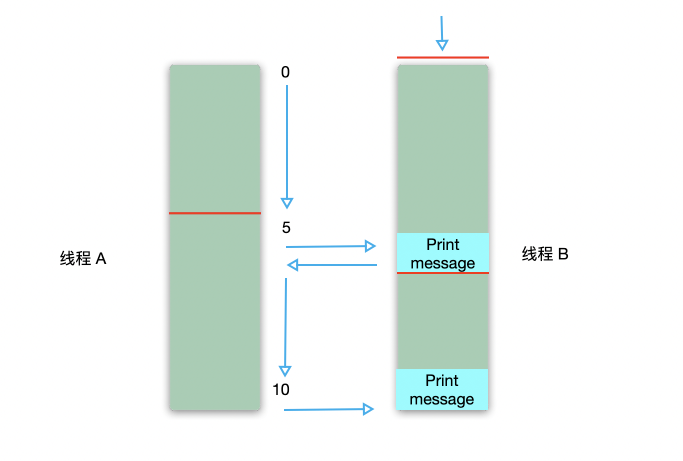
ThreadLocal
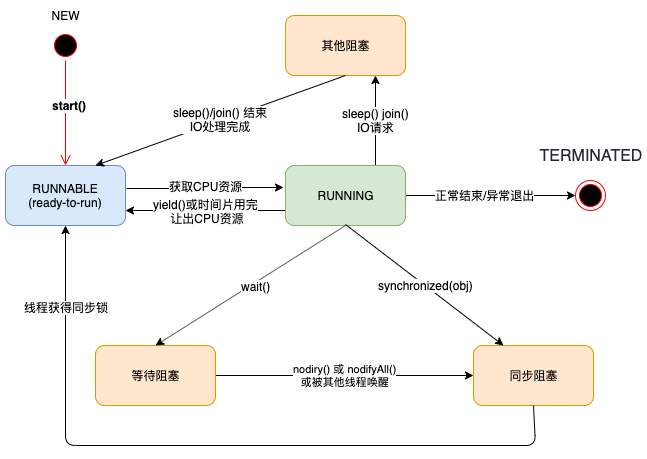
ThreadLocal 被称为线程本地变量,每个线程都单独有一份 ThreadLocal 。各线程之间的 ThreadLocal 是不共享的。在[多线程与高并发](https://nanyiniu.github.io/2020/06/10/ 多线程与高并发 /) 中,谈到进程时,各个进程之间是相互独立的,拥有独立的运行空间、内存。而 ThreadLocal 完成的工作就是在线程层级,做了独立的空间。
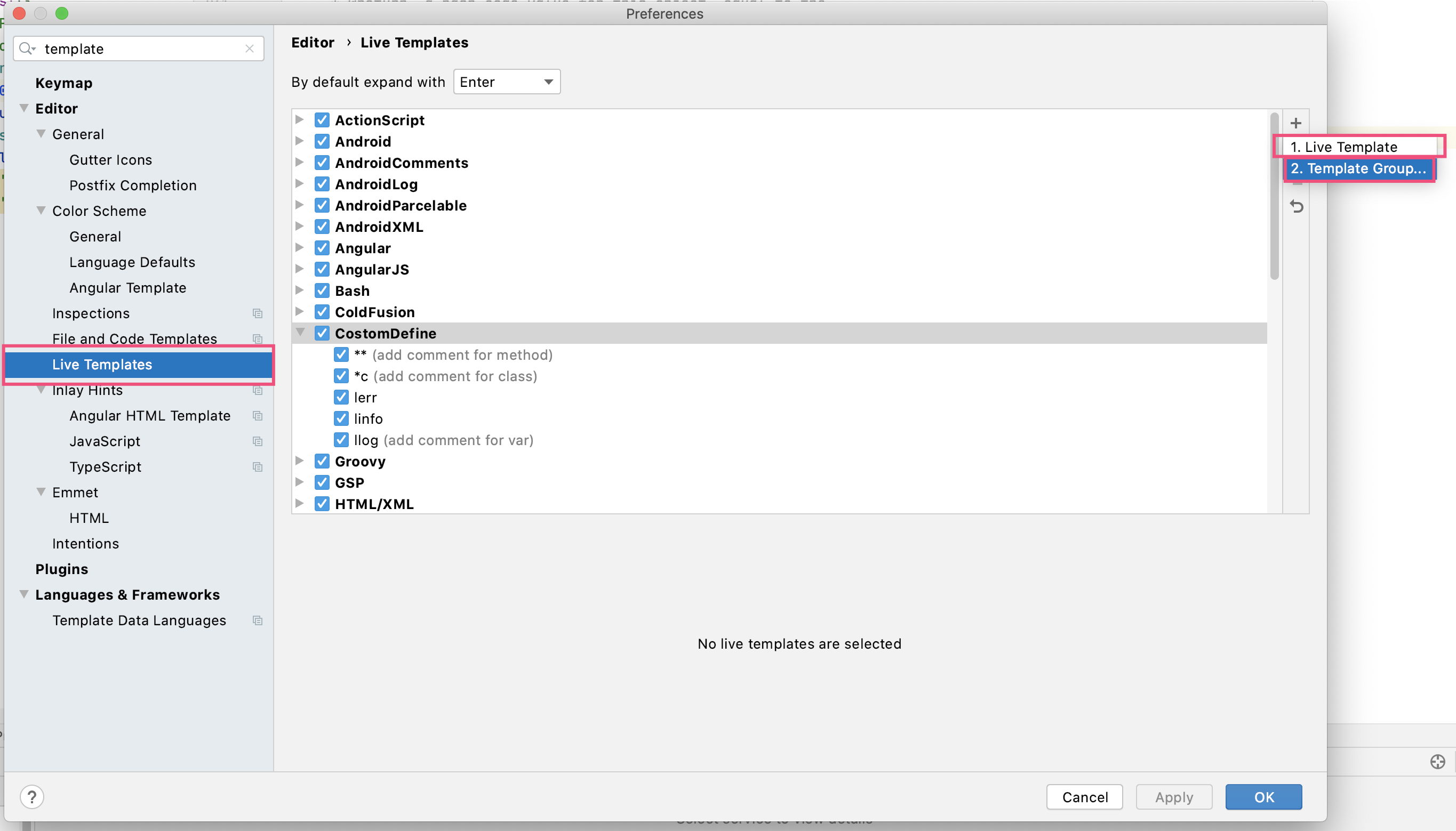
ThreadLocal 结构
ThreadLocal 本身不具备什么数据结构,他的实现是依附于 ThreadLocalMap 。
每次 ThreadLocal 执行 set 方法后,实际上是使用 ThreadLocalMap 的 set 方法,将 ThreadLocal 作为 key,value 作为 value 放入到 ThreadLocalMap 中。
而实际上的 ThreadLocalMap 是由 Entry 来实现,而 Entry 中的 key 是 WeakReference 包裹的 ThreadLocal。
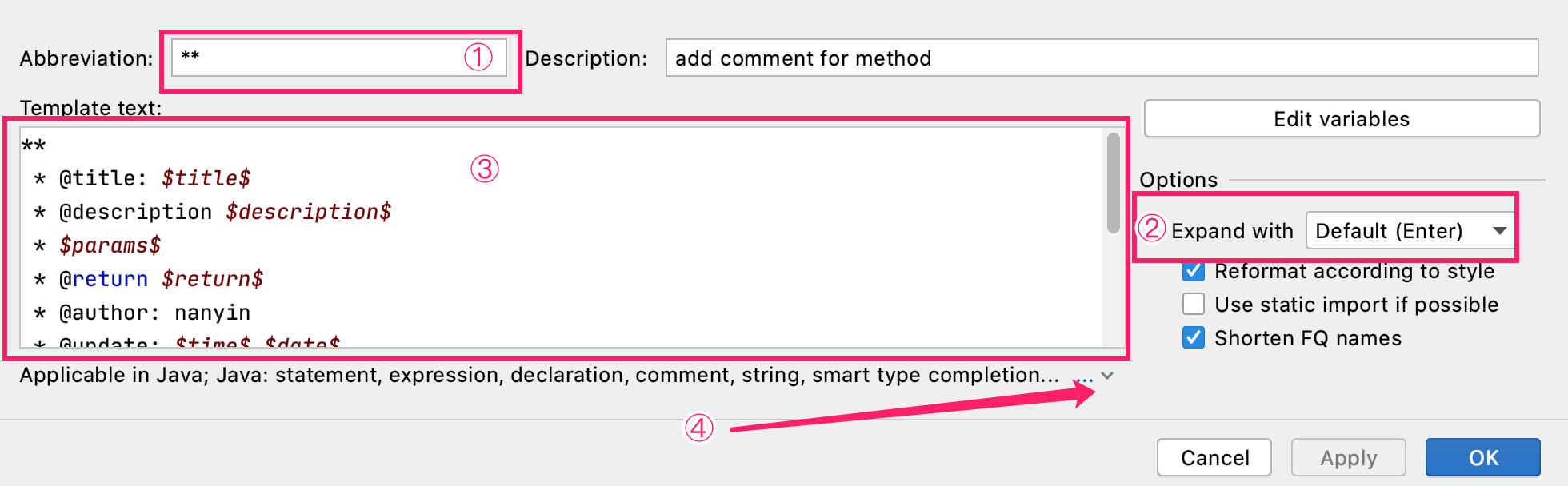
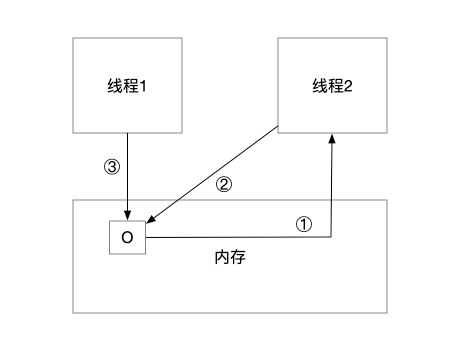
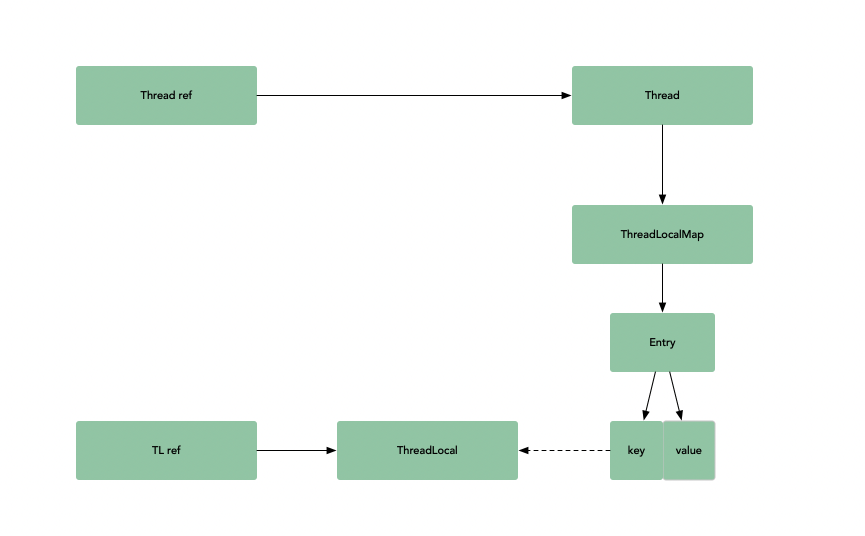
过程如下图:
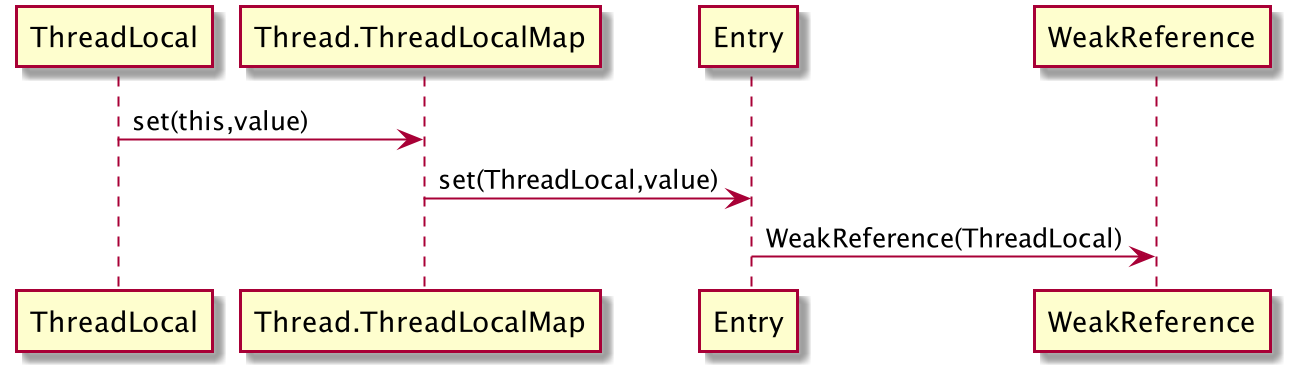
结构引用:其中虚线表示弱引用
为什么要使用弱引用?
原因在于防止内存溢出,那为什么弱引用就能够够避免呢?再次之前需要先了解什么是弱引用 ->Java 的四种引用类型。
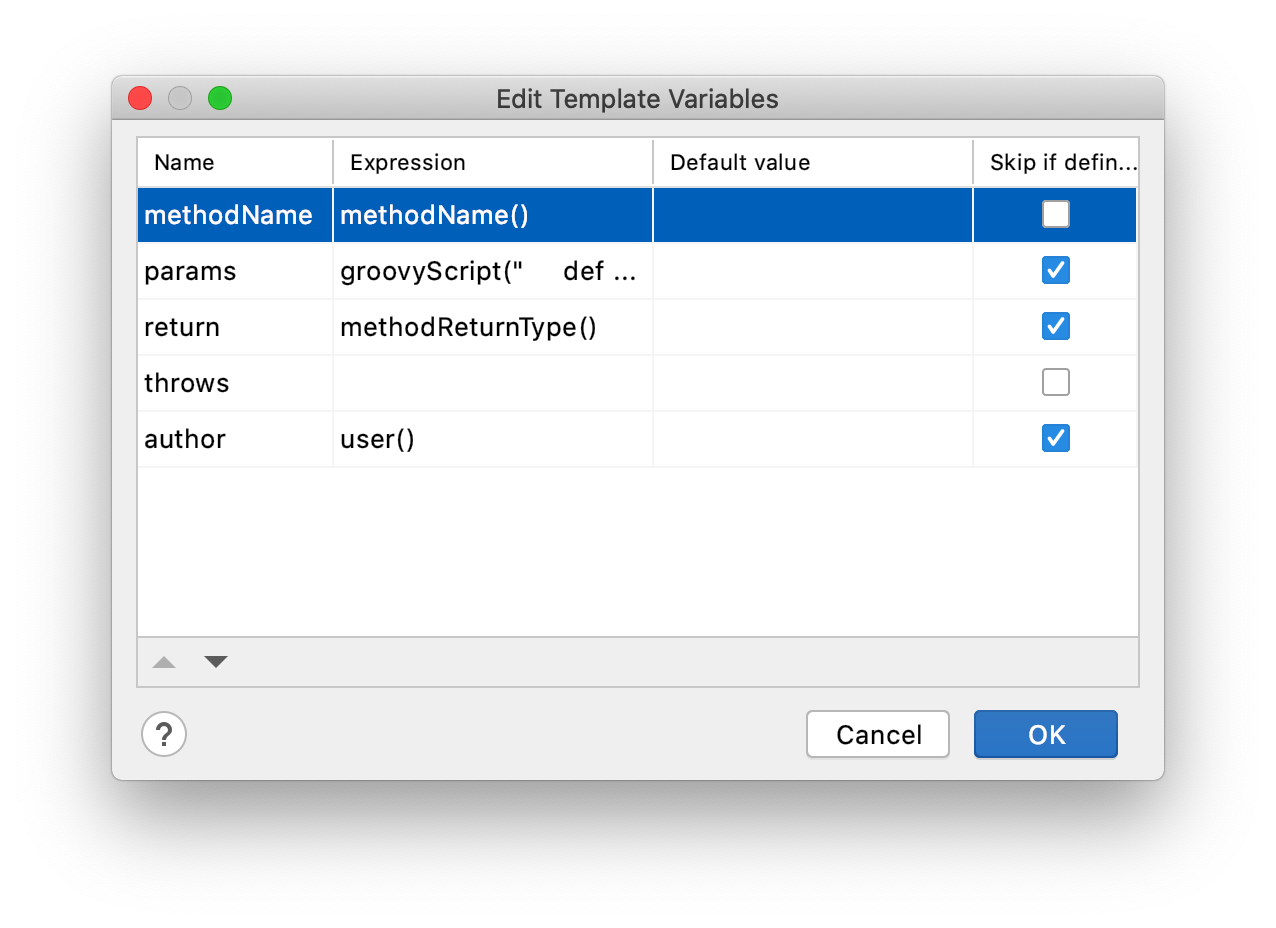
只要进行垃圾回收,那么弱引用就会被回收掉。那么,可以看图 2 中的结构。如果需要 ThreadLocal 引用被断开,也就是 TL ref 被设为 null,因为 ThreadLocal 与 Entry 中的 key 是弱引用关系,所以,只要这边的强引用(tl ref)断开,则下一次垃圾回收,就一定能把 ThreadLocal 回收掉。
如果不理解,那么举个反例,如果 ThreadLocal 与 Entry 中的 key 是强引用关系,此时 tl ref 和这个 threadlocal 断开。此时,还需要将 threadLocalMap 这边的引用断开,才能够将 threadlocal 进行回收,而 threadLocalMap 是线程 Thread 中的一部分,声明周期和 Thread 相同。所以,造成的结果就是,只要线程运行着,threadLocal 就不会被回收。
ThreadLocal 的内存溢出
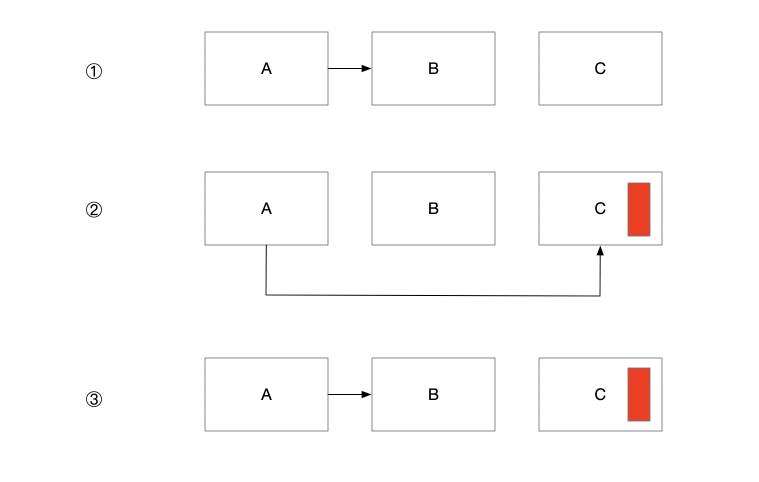
除去上面分析的如果使用强引用会导致内存溢出外,还有一种情况会导致 ThreadLocal 的内存溢出
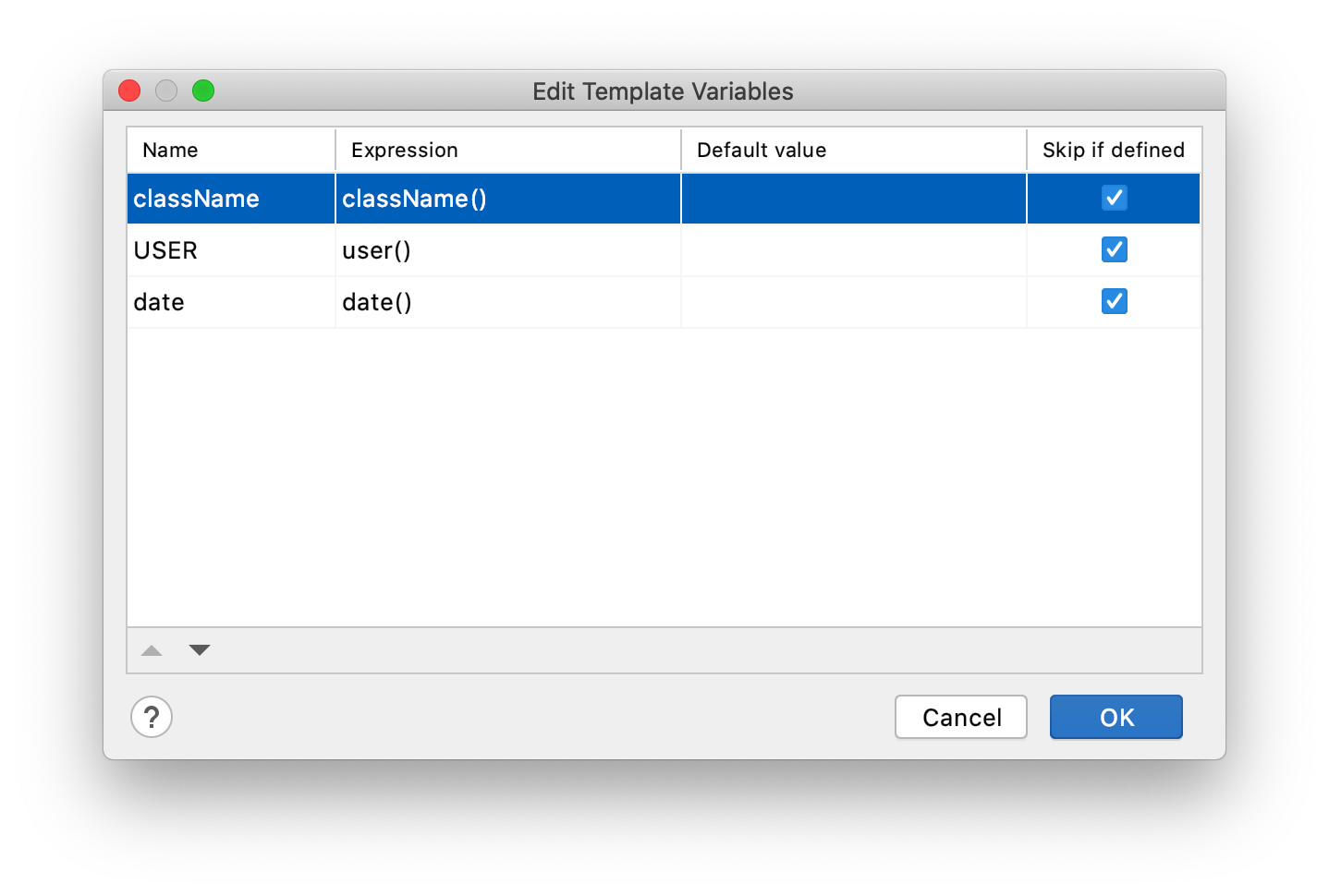
如果 tl ref 和 threadLocal 之间的强引用断开后,此时的 threadlocal 变为 null 存在于 Entry 中,也就是说内存中保存着 key 为 null 的 entry,同样无法回收,导致内存溢出。
解决方式是,用完 threadLocal 后,使用 remove 方法进行手动释放。