设计模式之责任链模式
责任链模式是一种对象的行为模式.通过为多个对象处理客户端请求的方式,实现降低发送者与接收者之间的耦合性.对象链由一个对象对下一个对象的引用组成一条链,请求在这个链上传递,直到这个链上的某一个对象处理它.
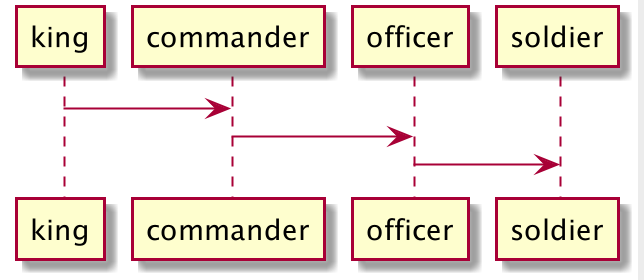
King只需要下达命令,具体谁来做并不关心,然而这个命令会通过commander, officer,soldier,这三类人只需要来执行各自负责的部分,如果没有自己负责的那么就给下一个职责的人就行了.这就是责任链模式.下面根据例子类图来分析责任链中的结构关系.
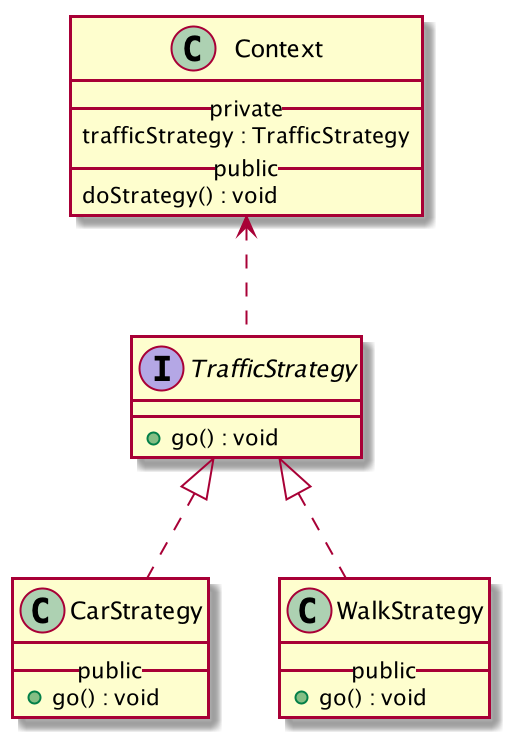
责任链的结构
责任链的基本机构由下面三部分组成:
- 抽象处理者 RequestHandler,定义接口方法,使用handler方法规定实现类通过该方法来规范子类的实现.
- 具体处理者 通过继承RequestHandler实现其中的handle方法
- 请求Request,客户端通过方法将request放入处理者链中,处理者一次执行这个request.request在构成的责任链上进行传递,具体处理人根据条件判断是否需要处理,如果不需要处理,流转至下一个人.
正常的责任链模式请求总是会被处理的,并且请求不会被多次处理.
在日常工作时,经常会遇到请假审批的情况.现在构建一个场景,当一个人在项目中,那么就让项目经理审批通过即可,否则需要他对应部门的主管审批通过.如张三发起请求,请求先到项目经理处,发现不属于项目成员,则再提交至张三的部门主管处,进行审批.
责任链模式的使用环境
1、有多个对象可以处理同一个请求,具体哪个对象处理该请求由运行时刻自动确定。
2、在不明确指定接收者的情况下,向多个对象中的一个提交一个请求。
3、可动态指定一组对象处理请求
场景实现
通过类图可以看到继承和调用关系:
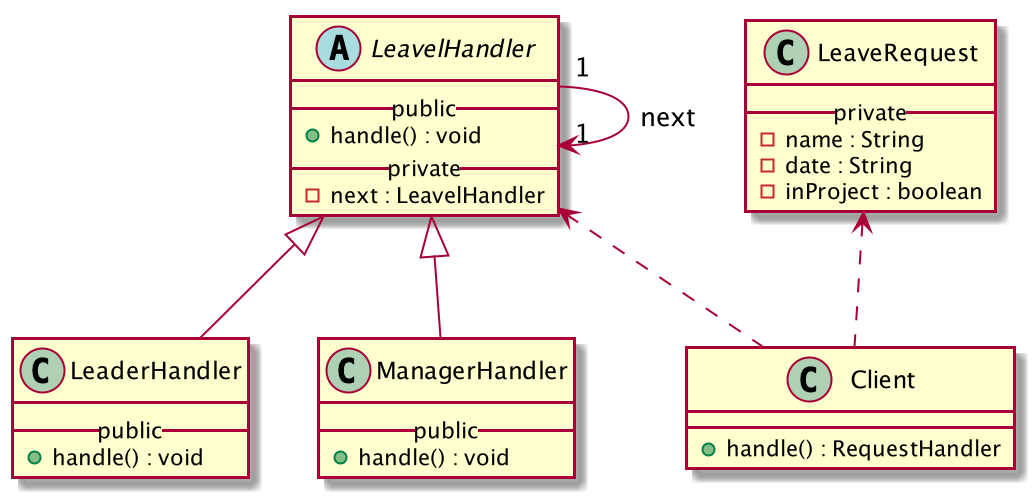
下面看具体实现:
- 抽象处理者,定义一个LeaveHandler,作为请假处理人的抽象类
1 | public abstract class LeaveHandler { |
- 具体处理者,定义两个具体处理人,分别为部门主管的
LeaderHandler和 项目主管的ManagerHandler都继承自抽象类
1 | public class ManagerHandler extends LeaveHandler { |
- 请求Request,定义一个请假请求LeaveRequest,包含请假人姓名和请求时间
1 | public class LeaveRequest { |
- client 调用者执行请假的流程
1 | public class Client { |
最后的执行结果:
1 | 项目经理对zhangsan在0919请假审批通过!! |