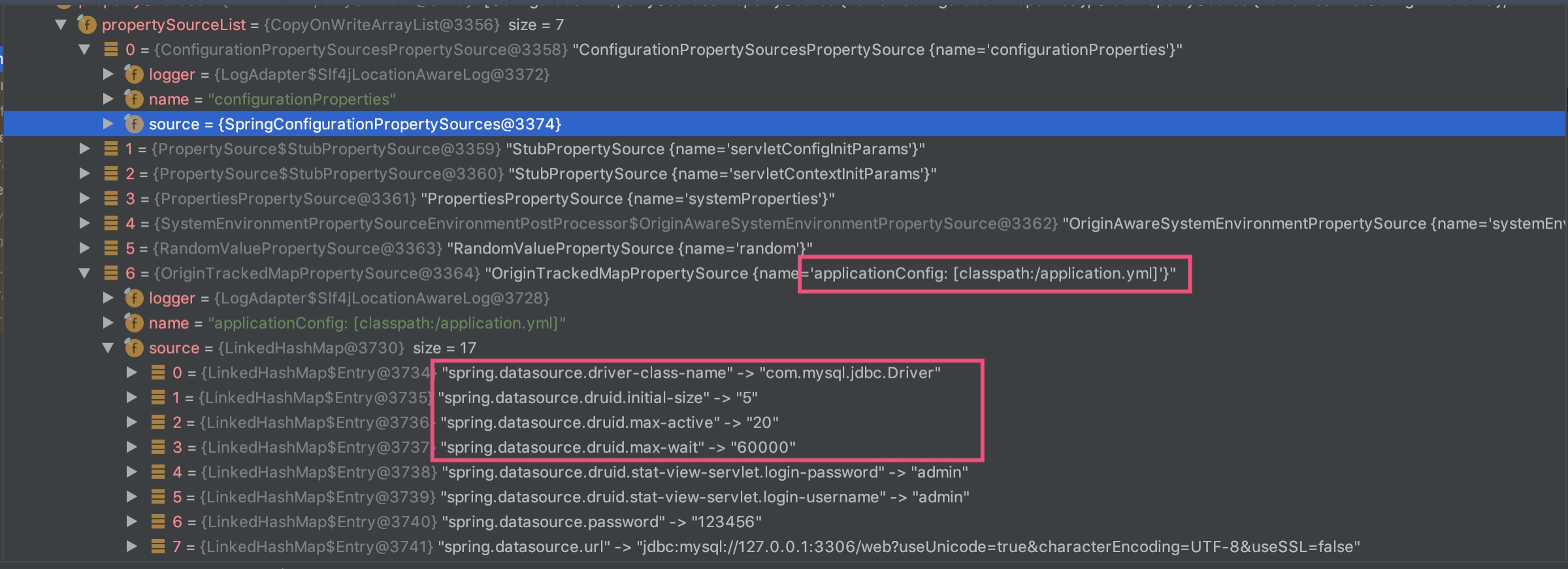
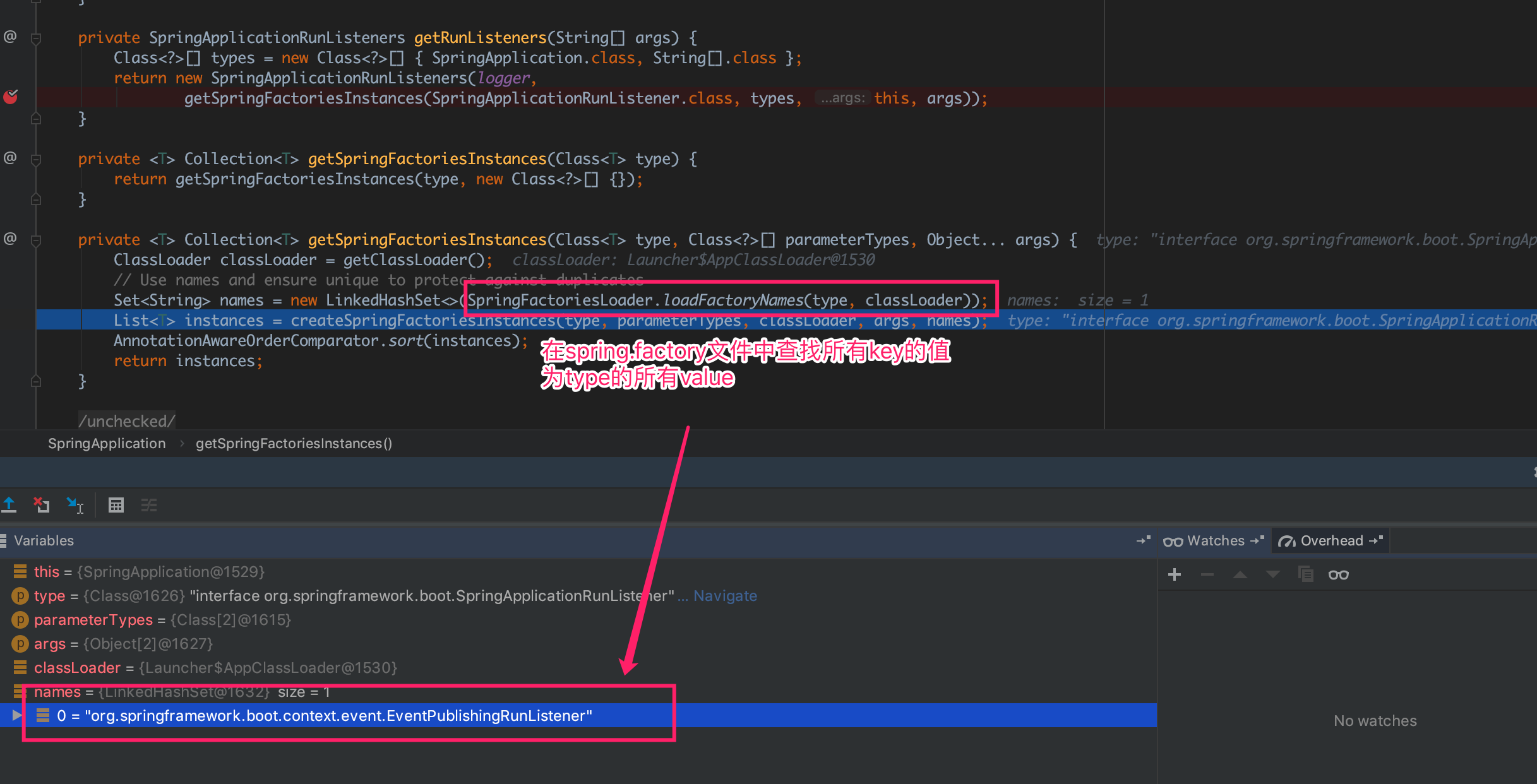
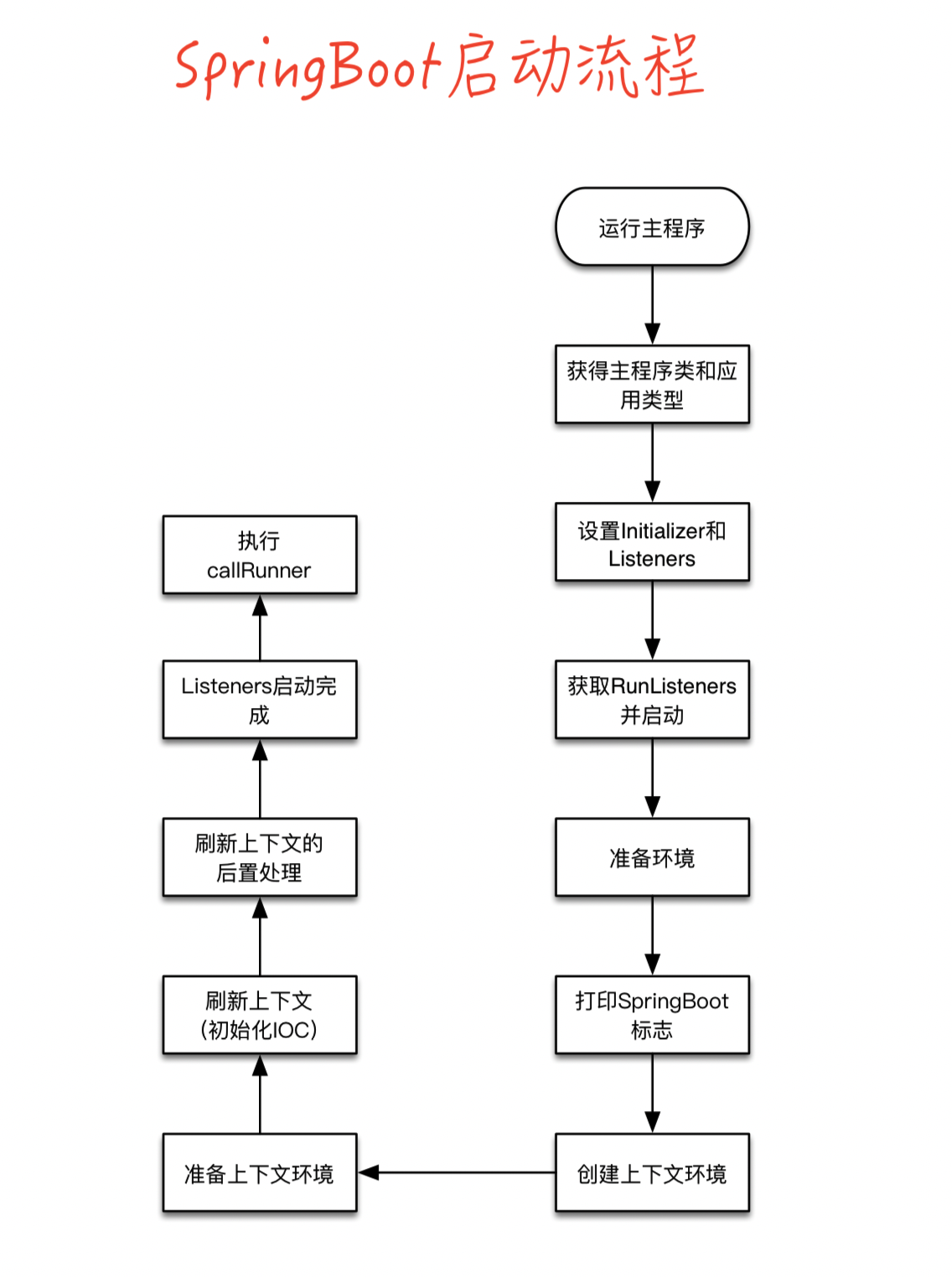
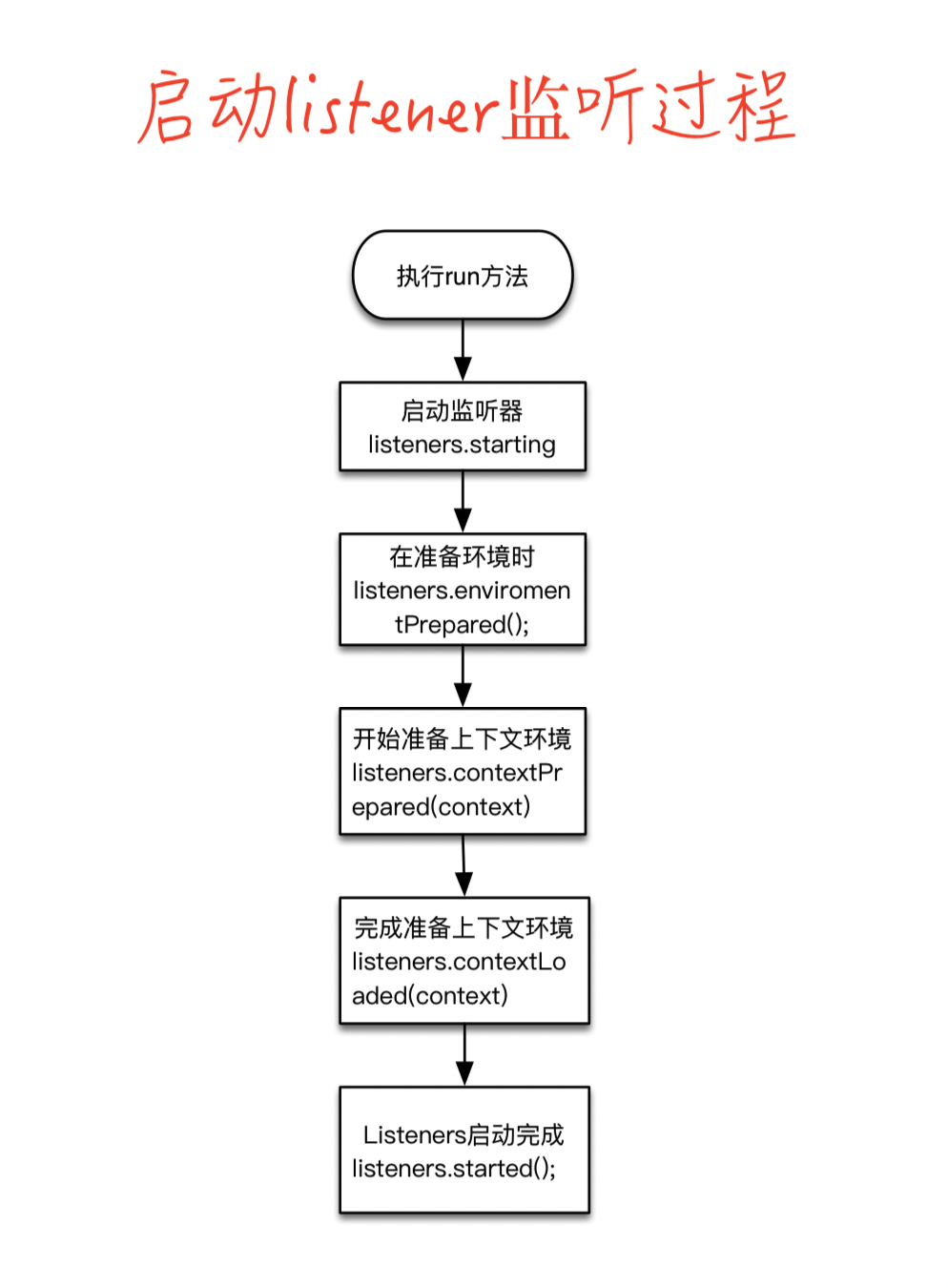
Bean的实例化
在refresh方法执行到 finishBeanFacotyInitializawtion 时,在方法内部会执行对Bean的实例化操作:
1 | // Instantiate all remaining (non-lazy-init) singletons. |
重点在于 preInstantiateSingletons 方法,用来初始化所有的单例Bean。实际上在前面的getBean获取weaverAware就能够看出真正调用获取单实例的Bean的方法就是 getBean 方法。
1 | public void preInstantiateSingletons() throws BeansException { |
在preInstantiateSingletons 中,可以看到它会遍历所有的已经注册到容器中的Bean,最后会通过 getBean() 进行对Bean的初始化操作。
其中判断了如果是 Factorybean 的情况下应该先去添加一个前缀 ‘&’ ,才能获取真正的FactoryBean的实现类的对象Bean。如果不添加前缀 ‘&’,则会返回实现类中的getObject方法返回的对象。
因为经过分析,是 getBean 方法是达到初始化Bean实例的目的,所以接下来看 getBean 中是如何实现的。
getBean
getBean方法比较复杂,所以我依据调用顺序拆出来大致5个小章节来展开讲。
1.getBean通过调用doGetBean创建实例
1 | public Object getBean(String name) throws BeansException { |
2. 检查缓存中是否存在
调用doGetBean方法后,首先会先使用getSingleton方法判断缓存中是否存在实例,会执行以下逻辑:
- 判断缓存中是否存在?
- 如果存在,如果当前单例正在创建中,则说明出现了循环引用。
- 如果存在,实例没有正在创建,没有循环引用。
- 只要缓存中存在,都直接返回缓存中的BeanInstance
1 | protected <T> T doGetBean(final String name, @Nullable final Class<T> requiredType, |
3. 如果typeCheckOnly为false,则标记已创建
作用是:将指定的bean标记为已创建,允许bean工厂优化其缓存以重复创建指定的bean。
4. 获取depend-on的Bean,先对其进行register和实例化
需要注意的是,这里的 depend-on 的内容是使用 @DependsOn 注解指定的BeanName(注解方式)
1 | // 获得RootBeanDefinition |
5.调用createBean创建Bean实例
在使用createBean创建Bean时,会通过 Object bean = resolveBeforeInstantiation(beanName, mbdToUse);来处理初始化Bean前置方法触发AOP的功能。
1 | protected Object resolveBeforeInstantiation(String beanName, RootBeanDefinition mbd) { |
如果存在需要创建Proxy代理Bean,则先去创建代理Bean,在创建完后,则会开始调用 doCreateBean 方法创建Bean实例。
接着调用 Object beanInstance = doCreateBean(beanName, mbdToUse, args); 创建实例,并返回一个Object的类型的beanInstance
doCreateBean这个方法比较长,大致能通过这几步完成这个方法;
- 使用
createBeanInstance创建一个包装Bean - 允许
MergedBeanPostProcessor使用后置方法处理包装后的Bean - 如果
allowCircularReferences属性为true,则先获取 达到这个Bean的早期的ref ,用来 防止Bean在生成时循环引用 的问题,后面会详细讲这里是如果获取早期的ref应用,和又是如何防止Bean的循环应用的问题。 - 通过
populateBean方法为Bean进行赋值,包括依赖!! - 通过
initializeBean方法,执行各种初始化方法和前、后置方法。 - 通过三级缓存机制,用来防止出现循环引用的问题。
- 注册Bean为一次性的
createBeanInstance 创建一个包装Bean
1 | protected BeanWrapper createBeanInstance(String beanName, RootBeanDefinition mbd, @Nullable Object[] args) { |
如果使用默认的无参数构造起,会调用beanInstance = getInstantiationStrategy().instantiate(mbd, beanName, parent); 获取使用反射生成的实例。
1 | // 检测 bean 配置中是否配置了 lookup-method 或 replace-method |
知道最后使用Constructor.newInstance创建一个对象。
先缓存早期的实例
Spring中存在三层缓存,分别为第一级的 singletonObjects 、第二级的 earlySingletonObjects 、第三级的singletonFactories。
1 | /** Cache of singleton objects: bean name to bean instance. */ |
那么,Spring如何依靠这三级缓存来防止循环引用(circular references)的作用的呢?先通过下面的图片来简单了解下,当发生循环引用时,Spring如何使用三级缓存的。
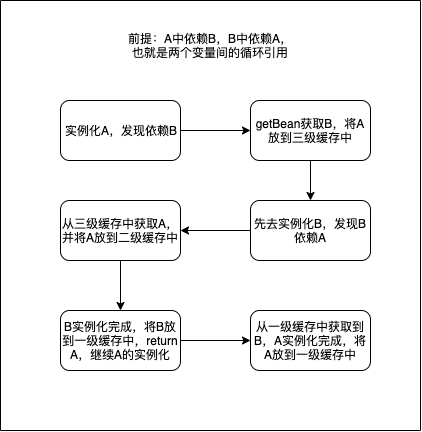
如图中所示,对象A依赖于对象B,而对象B依赖对象A的情况。下面根据图中各节点情况来具体分析代码的实现:
1. 实例化A,发现依赖B
在初始化A的过程中,会调用 populateBean 方法进行属性的赋值,其中 AutoWired 的类型来分别处理(By Name 还是 By Type),
但不管是哪个类型,最后都会使用 getBean 来先获取依赖。
2. 获取B,将A放到三级缓存中
其实在进行A的属性赋值前,就已经通过 doCreateBean 方法中的 addSingletonFactory 方法将A放到三级缓存中:
1 | boolean earlySingletonExposure = (mbd.isSingleton() && this.allowCircularReferences && |
3. 实例化B,发现依赖A
在上一步中,A依赖B,会调用getBean先去获取B,但同样在doCreateBean 方法中的 populateBean 方法中同样会调用 getBean 先去获取依赖A。
1 | Object sharedInstance = getSingleton(beanName); |
通过getSingleton方法从三级缓存获取bean,如果成功的在第三级缓存中找到Bean,则移除第三级缓存中的Bean,并放到二级缓存中。
1 | protected Object getSingleton(String beanName, boolean allowEarlyReference) { |
4. 实例化完成,将B放到一级缓存中
在调用doGetBean方法时,会通过 getSingleton方法中的addSingleton将实例添加到一级缓存中:
1 | sharedInstance = getSingleton(beanName, () -> { |
在getSingleton中调用了addSingleton(beanName, singletonObject),将完成的实例放到一级缓存中。
1 | protected void addSingleton(String beanName, Object singletonObject) { |
5. 返回A的创建过程,继续创建A
最后创建完成A后,同样会将A放到一级缓存中。至此对象A,对象B全部创建完成。利用了三级缓存机制避免了循环引用。
populateBean 执行Bean的初始化
在上一节中提到了,初始化对象时,需要调用populateBean(beanName, mbd, instanceWrapper)该方法来达到属性值的填充。
忽略 BeanPostProcessor后置处理器,那么实际上步骤比较简单明了:
- 如果不存在属性值,则直接返回,跳过这个方法。
- 如果存在,先获得所有的属性值,依据AutoWired属性,将依赖项注入到容器中
- 最后进行真正的属性填充
1. 检查是否存在属性
1 | if (bw == null) { |
2.依据ByName还是ByType进行属性的注入
1 | // 获得属性 |
根据 resolvedAutowireMode 的值的不同,选择不同的装配方式
- 按名称注入,使用@Autowired默认的方式
- 按类型注入,使用@Resource或者使用JSR330标准中的@Inject注解的默认方式
但是,不管依赖哪种方式进行装配,最后都会使用getBean来获取属性依赖,装配到容器中,并将值放到 newPvs 等待填充。
3.属性填充
最后通过使用 applyPropertyValues 方法实现属性的填充:
主要步骤如下:
- 如果pvs是空的,则直接返回
- 否则创建一个
deep copy,用于解决所有对值的引用,对未被解析的先解析&&已解析的直接加入deepCopy中。 - 获取到
deepCopy后,使用setPropertyValues添加到BeanWrapper中
1 | protected void applyPropertyValues(String beanName, BeanDefinition mbd, BeanWrapper bw, PropertyValues pvs) { |
initializeBean 初始化Bean
在使用populateBean后,调用initializeBean方法进行bean的init,在init方法内部,可分为一下几部分调用
- invokeAwareMethods 方法,设置Aware属性
- applyBeanPostProcessorsBeforeInitialization 方法,调用 BeanProcessor中的Bean初始化前的后置方法
- invokeInitMethods 方法,激活自定义的init方法
- 执行BeanProcessor中的初始化后的后置方法
1. invokeAwareMethods
寻找是否满足特定的条件,如果满足则进行相关属性的填充
1 | private void invokeAwareMethods(final String beanName, final Object bean) { |
2. applyBeanPostProcessorsBeforeInitialization
循环容器中每一个BeanPostProcessor,执行BeanPostProcessor的postProcessBeforeInitialization方法。
1 | public Object applyBeanPostProcessorsBeforeInitialization(Object existingBean, String beanName) |
3.invokeInitMethods 执行init方法
如果是isInitializingBean则先会执行自己的内置方法afterPropertiesSet。如果制定了initMethod,那么后续会通过反射执行这个方法
1 | protected void invokeInitMethods(String beanName, final Object bean, @Nullable RootBeanDefinition mbd) |
4.applyBeanPostProcessorsAfterInitialization
循环容器中每一个BeanPostProcessor,执行BeanPostProcessor的 postProcessAfterInitialization 方法。
至此Bean的实例化过程就大致完成了。